Flink基本知识
— Bigdata, Flink — 15 min read
Flink 基本概念
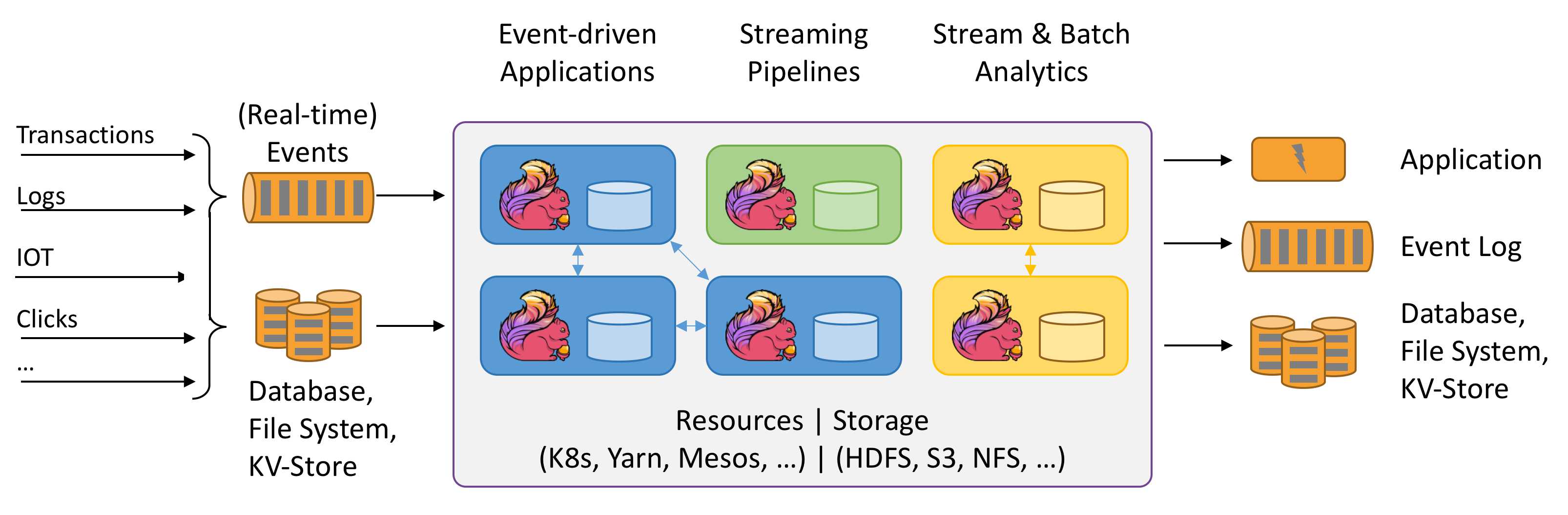
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计�算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
名词介绍
整体组件
下面的图片可点击模块跳转至官方说明

-
Deployment层。该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN),(GCE/EC200)。
-
Runtime层。Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处��理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
-
API层: 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
-
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)
流
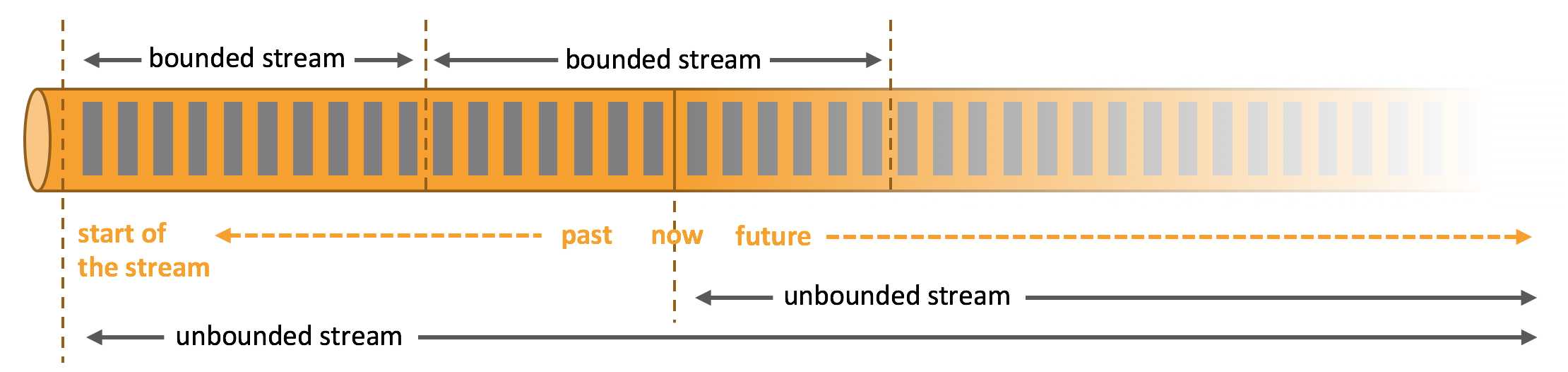
- 有界流(Bounded) 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 无界流(Unbounded) 有定义流的开始,也有定义流的结束。有界流可以在摄取所有��数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
数据流编程模型
分布式运行环境
状态
时间
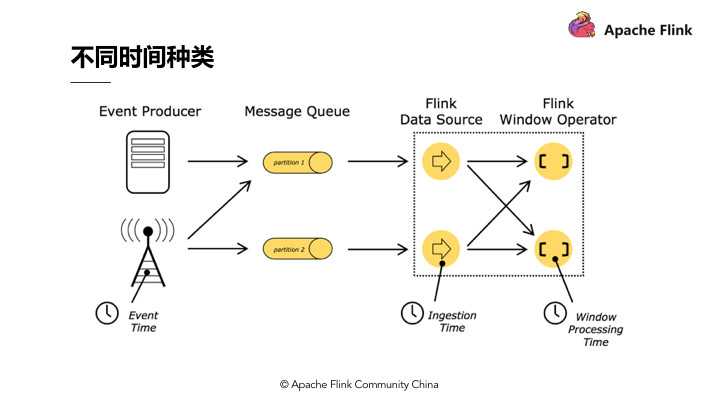
Time
-
Event Time 是每条数据在其生产设备上发生的时间。这段时间通常嵌入在记录数据中,然后进入Flink,可以从记录中提取事件的时间戳;Event Time即使在数据发生乱序,延迟或者从备份或持久性日志中重新获取数据的情况下,也能提供正确的结果。这个时间是最有价值的,和挂在任何电脑/操作系统的时钟时间无关。
-
Ingestion Time 是指执行相应操作的机器的系统时间。如果流计算系统基于Processing Time来处理,对流处理系统来说是最简单的,所有基于时间的操作(如Time Window)将使用运行相应算子的机器的系统时钟。然而,在分布式和异步环境中,Processing Time并不能保证确定性,它容易受到Event到达系统的速度(例如来自消息队列)以及数据在Flink系统内部处理的先后顺序的影响,所以Processing Time不能准确地反应数据发生的时间序列情况
-
Processing Time
是事件进入Flink的时��间。 在Source算子处产生,也就是在Source处获取到这个数据的时间,Ingestion Time在概念上位于Event Time和Processing Time之间。在Source处获取数据的时间,不受Flink分布式系统内部处理Event的先后顺序和数据传输的影响,相对稳定一些,但是Ingestion Time和Processing Time一样,不能准确地反应数据发生的时间序列情况。
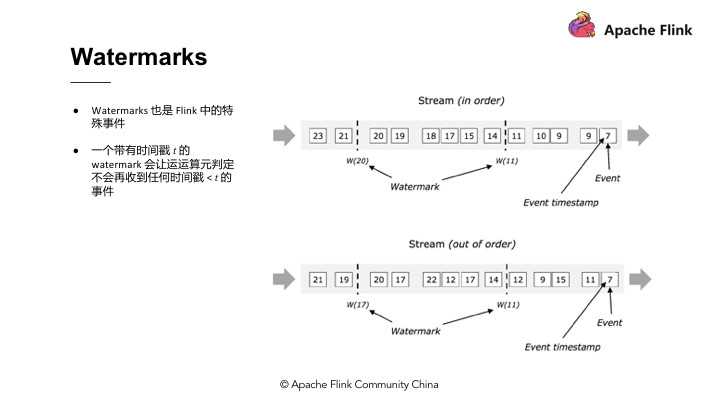
Watermarks
Flink实际上是用 Watermarks 来实现Event – Time 的功能。Watermarks 在Flink 中也属于特殊事件,其精髓在于当某个运算值收到带有时间戳“ T ”的 Watermarks 时就意味着它不会接收到新的数据了。使用Watermarks 的好处在于可以准确预估收到数据的截止时间。举例,假设预期收到数据时间与输出结果时间的时间差延迟5 分钟,那么Flink 中所有的 Windows Operator 搜索3 点至4 点的数据,但因为存在延迟需要再多等5分钟直至收集完4:05 分的数据,此时方能判定4 点钟的资料收集完成了,然后才会产出3 点至4 点的数据结果。这个时间段的结果对应的就是 Watermarks 的部分。
Window
Apache Flink(以下简称 Flink) 是一个天然支持无限流数据处理的分布式计算框架,在 Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 Flink 中 Window 可以是时间驱动的(Time Window),也可以是数据驱动的(Count Window)。下面的代码是在 Flink 中使用 Window 的两个示例


Runtime架构
Flink 是可以运行在多种不同的环境中的,例如,它可以通过单进程多线程的方式直接运行,从而提供调试的能力。它也可以运行在 Yarn 或者 K8S 这种资源管理系统上面,也可以在各种云环境中执行。针对不同的执行环境,Flink 提供了一套统一的分布式作业执行引擎,也就是 Flink Runtime 这层。Flink 在 Runtime 层之上提供了 DataStream 和 DataSet 两套 API,分别用来编写流作业与批作业,以及一组更高级的 API 来简化特定作业的编写
Flink Runtime 层的主要架构如下图所示,整体来说,它采用了标准 master-slave 的结构,其中左侧白色圈中的部分即是 master,它负责管理整个集群中的资源和作业;而右侧的两个 TaskExecutor 则是 Slave,负责提供具体的资源并实际执行作业。
其中,Master 部分又包含了三个组件,即 Dispatcher、ResourceManager 和 JobManager。其中,Dispatcher 负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager 组件。ResourceManager 负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager。JobManager 负责管理作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业都有自己的 JobManager 组件。这三个组件都包含在 AppMaster 进��程中。
基于上述结构,当用户提交作业的时候,提交脚本会首先启动一个 Client进程负责作业的编译与提交。它首先将用户编写的代码编译为一个 JobGraph,在这个过程,它还会进行一些检查或优化等工作,例如判断哪些 Operator 可以 Chain 到同一个 Task 中。然后,Client 将产生的 JobGraph 提交到集群中执行。此时有两种情况,一种是类似于 Standalone 这种 Session 模式,AM 会预先启动,此时 Client 直接与 Dispatcher 建立连接并提交作业即可。另一种是 Per-Job 模式,AM 不会预先启动,此时 Client 将首先向资源管理系统 (如Yarn、K8S)申请资源来启动 AM,然后再向 AM 中的 Dispatcher 提交作业。
当作业到 Dispatcher 后,Dispatcher 会首先启动一个 JobManager 组件,然后 JobManager 会向 ResourceManager 申请资源来启动作业中具体的任务。这时根据 Session 和 Per-Job 模式的区别, TaskExecutor 可能已经启动或者尚未启动。如果是前者,此时 ResourceManager 中已有记录了 TaskExecutor 注册的资源,可以直接选取空闲资源进行分配。否则,ResourceManager 也需要首先向外部资源管理系统申请资源来启动 TaskExecutor,然后等待 TaskExecutor 注册相应资源后再继续选择空闲资源进程分配。目前 Flink 中 TaskExecutor 的资源是通过 Slot 来描述的,一个 Slot 一般可以执行一个具体的 Task,但在一些情况下也可以执行多个相关联的 Task,这部分内容将在下文进行详述。ResourceManager 选择到空闲的 Slot 之后,就会通知相应的 TM “将该 Slot 分配分 JobManager XX ”,然后 TaskExecutor 进行相应的记录后,会向 JobManager 进行注册。JobManager 收到 TaskExecutor 注册上来的 Slot 后,就可以实际提交 Task 了。
TaskExecutor 收到 JobManager 提交的 Task 之后,会启动一个新的线��程来执行该 Task。Task 启动后就会开始进行预先指定的计算,并通过数据 Shuffle 模块互相交换数据。
以上就是 Flink Runtime 层执行作业的基本流程。可以看出,Flink 支持两种不同的模式,即 Per-job 模式与 Session 模式。如图 3 所示,Per-job 模式下整个 Flink 集群只执行单个作业,即每个作业会独享 Dispatcher 和 ResourceManager 组件。此外,Per-job 模式下 AppMaster 和 TaskExecutor 都是按需申请的。因此,Per-job 模式更适合运行执行时间较长的大作业,这些作业对稳定性要求较高,并且对申请资源的时间不敏感。与之对应,在 Session 模式下,Flink 预先启动 AppMaster 以及一组 TaskExecutor,然后在整个集群的生命周期中会执行多个作业。可以看出,Session 模式更适合规模小,执行时间短的作业。

Transformation
Transformation操作将1个或多个DataStream转换为新的DataStream,多个转换组合成复杂的数据流拓扑,如下图所示,DataStream会由不同的Transformation操作、转换、过滤、聚合成其他不同的流,从而完成业务要求;
Shuffle 机制
执行图
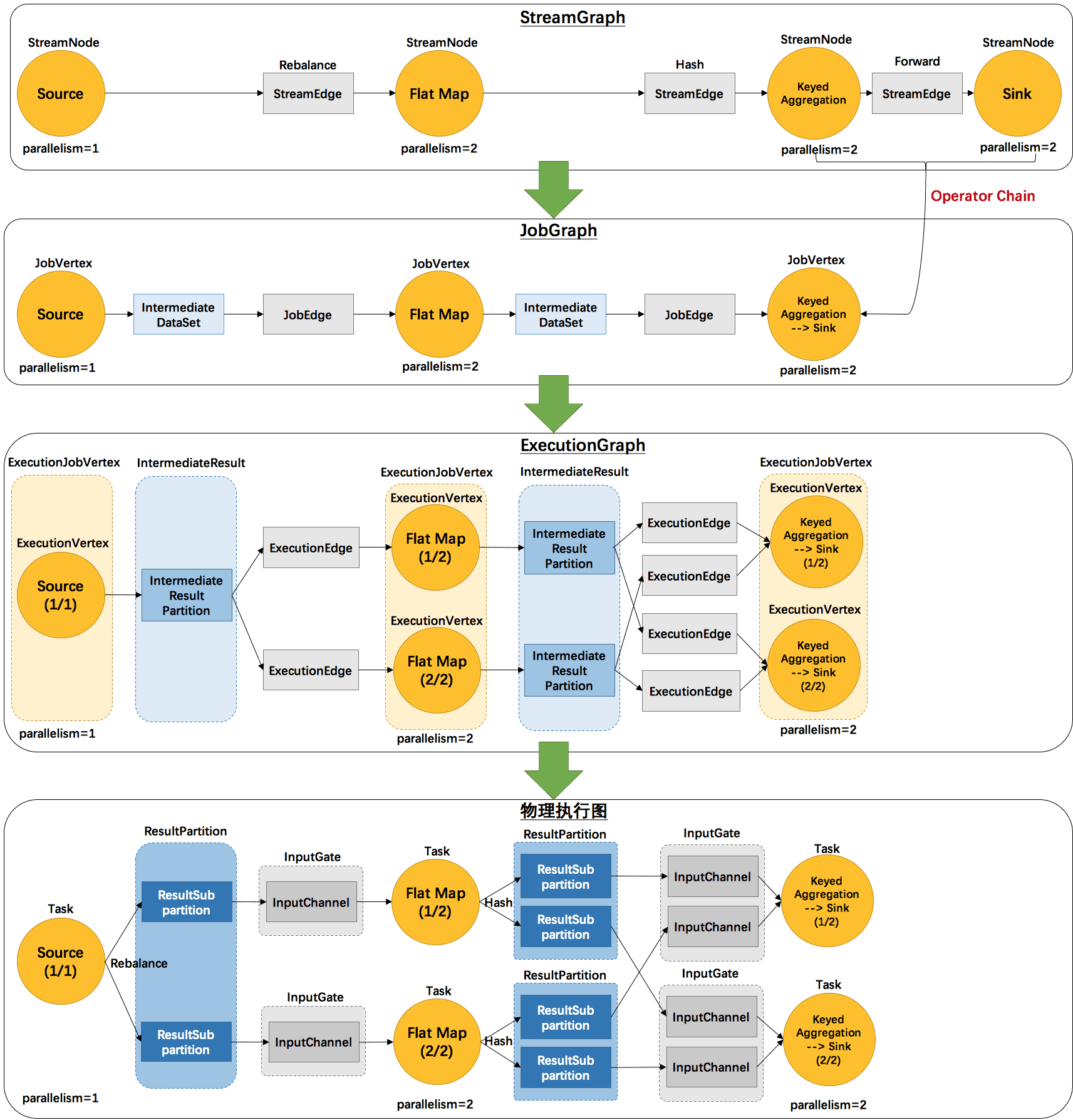
由 Flink 程序直接映射成的数据流图是 StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink 需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph : JobManager 根据 JobGraph 生成 ExecutionGraph 。 ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。